
Large Language Models – A look at the challenges for the developers and latest solutions to them
OpenAI revolutionised the AI landscape with the release of ChatGPT in November 2022. ChatGPT is a family of Gen AI chatbots that utilise a large language model (LLM) based on the Transformer architecture (a type of Deep Learning/Neural Network) to understand and generate human-like text in a conversational context. Generative AI refers to a class of artificial intelligence that can generate new content, such as text, images, music, or even video, rather than just analysing, classifying existing data or making predictions. LLM or Large Language Model are the backbone of text-based Gen AI and help in understanding and generating human text. In turn LLMs are based on vast amounts of text data sourced from the internet including websites, books, articles, research papers, forums, social media, and more.
The most common implementation of LLMI these days is to pick an off the shelf Gen AI model, integrate it in a website/app after ensuring that the answers generated are in the context of the use case i.e. banking website should not be answering questions on how to plan a vacation. There are several ways to do it.
- Prompt Engineering – Using examples guide the model to generate accurate, relevant, and coherent responses for a given task or scenario.
- Fine Tuning/Transfer Learning – Taking a pre-trained model and further training it on a smaller, task-specific dataset to adapt it to a specific task or domain. It is a resource intensive exercise and not suitable for use cases where frequent updates are made to the data.
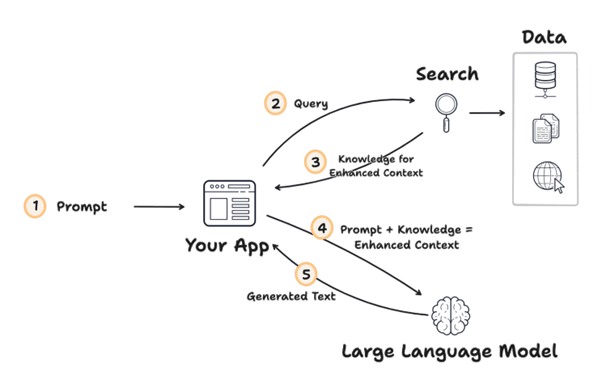
- Retrieval-Augmented Generation – Effectively combine information retrieval and text generation. This approach leverages the strengths of both components to deliver highly accurate, contextually relevant, and up-to-date responses.
Despite these advancements the key areas of concern remain –
- Reliability – Generative AI models may produce unpredictable or unreliable outputs, the challenge is to detect such instances and quantify them. There are products in the market like Langsmith which can evaluate the outputs against a pre generated ground truth consisting of paired questions and their respective expected answers.
- Privacy and Security: The deployment of Gen AI systems in real-world applications raises concerns about data security, as malicious actors could exploit vulnerabilities in AI systems to access or manipulate sensitive information, e.g. a user accessing the annual report before its intended release to the public. Pinecone, a vector database provides a namespace feature for RAG implementations, which ensures that different users can search different subsets of the data based on their access level. Additionally large language models are trained on vast amounts of text data which may include copyrighted and classified information, posing legal issues.
- Latency: Refers to the time delay between the initiation of a process or request and the response or completion of that process or request. It’s a critical performance metric in various applications, especially those requiring real-time or near-real-time interaction. Caching, model pruning, quantization, hardware acceleration, and efficient software design can help address this.
- Environmental Impact: Training/Fine Tuning large language models requires significant computational resources, which can have a substantial environmental impact in terms of energy consumption and carbon emissions. If the use case permits a RAG based system or LoRA technique (Low-Rank Adaptation of Large Language Models) can be used to avoid this.
In the next part we will go through the code of GPT 2, understand embeddings and implement an LLM tackling the above issues.



{kind=link}
{kind=link}
{kind=link}
{kind=link}